FrontHub Lib Flow
FrontHub Lib Flow is a full automated workflow based in GitHub Flow to build consistent libraries.
Unlike a Micro Frontend, a library needs to strictly follow some rules to suit the ecosystem of npm packages. On top of these rules we created a simple yet extremely powerful workflow.
Git Workflow
This workflow works with the following branches:
main: it's the default and main branch of the repository. Everything in that branch is deployable.- Any other branch will be considered as a secondary branch, used for creating features, hot fixes, stating, etc.
There is a special branch called next to use in a case of a major version with a drastic architectural change that needs a long process of testing and adoption. Use this branch in extreme cases, maybe you'll never need it.
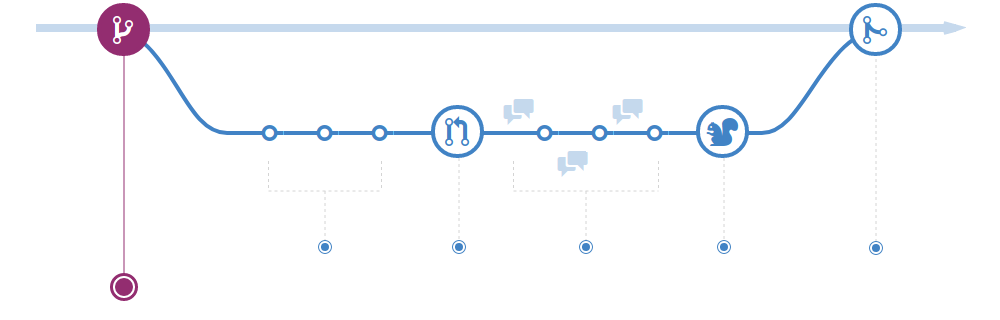
Below is the flow explained in detail, click on the tabs to see each part of the process:
- Create a branch
- Add commits
- Open a Pull Request
- Build (CI)
- Merge
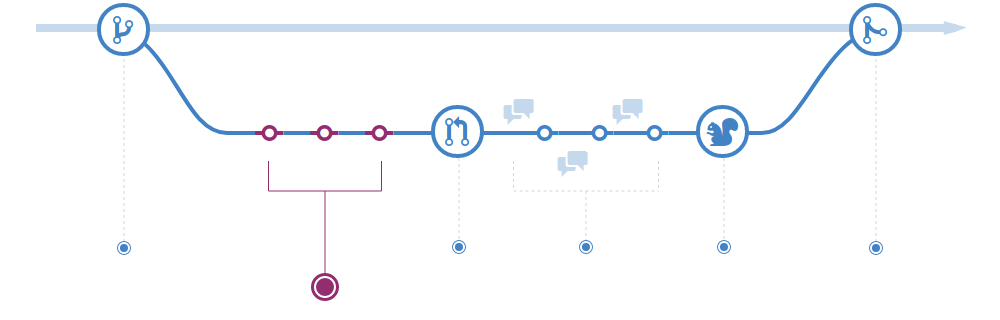
To initiate any changes to the project, it is necessary to create a new branch from the main branch.
The branch name makes no difference to the process, but it's good practice to give it very descriptive names, it helps to locate it and avoid collisions.
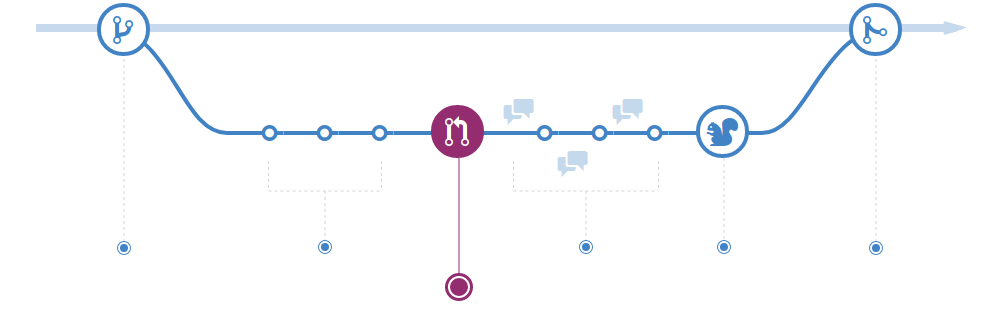
With the new branch created, make your commits to it.
The message of commits made on this branch is not relevant to the process. As in the end the squash merge will be done, what will be valid for the git log will be the title of the Pull Request. But if you want to micromanage the log in your project, set a non-restrictive standard so as not to impact the productivity of project contributors.
For safety and to share work progress, constantly push code to the server. As the build is only done in continuous integration (CI) with a Pull Request, it will not generate any waste of resources.
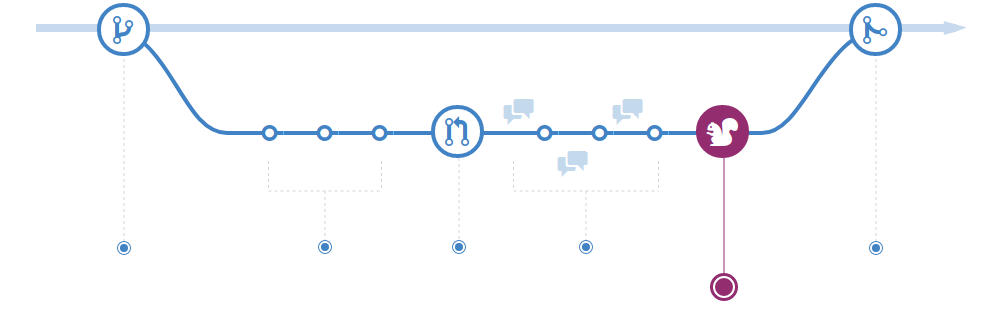
Once the work is done, start a pull request to share and initiate discussion about your commits.
When creating the Pull Request you must be attention to the following fields:
- Fill in the title descriptively, it will be the commit that will represent the entire branch when merging with the main branch.
- Add the label corresponding to the latest version that will be published, these labels are prefixed with
version:. For the latest version to be generated when merging this Pull Request and to generate acanaryrelease, also add theversion:releaselabel.
As long as Pull Request is open, you can continue to add new commits.
Once the Pull Request is created, or after any new commit with the Pull Request open, the build will start in continuous integration (CI) provider and will validate both the code and the Pull Request itself.
If all checks passes, and Pull Request has the label version:release, a canary version will be generated to be tested.
Every time the canary version is published, Pull Request will receive a comment with the new version with information on how to install it.
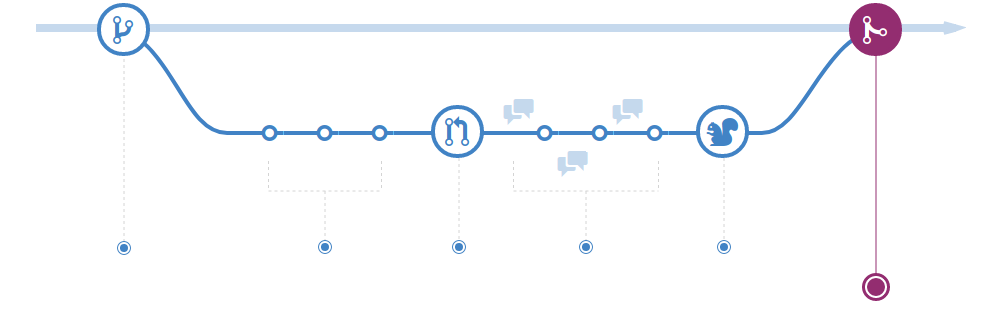
With Pull Request properly approved and tested, the way is clear to merge with the main branch.
Once merged, the main branch will receive a single commit (due to squash) that will trigger its build process. If the Pull Request has the version:release label then a new latest version will be generated.
Continuous Integration (CI)
Continuous Integration is a software development practice where members of a team integrate their work frequently, usually each person integrates at least daily - leading to multiple integrations per day. Each integration is verified by an automated build (including test) to detect integration errors as quickly as possible.
This flow reinforces the practice of continuous integration in its essence. In addition to the automated tests and validations that will be performed at each build, a ready-to-use version can be generated, called canary version, pushing the validation and testing options to the beyond.
Continuous Delivery (CD)
Continuous Delivery is a software development discipline where you build software in such a way that the software can be released to production at any time.
That's why it's so important to constantly push work to the main branch, and always have it ready to deploy, so it can be deployed constantly on demand.
This may sound a bit contrasting in that the final version is only published if the Pull Request is marked for it. But unlike a product for the end customer, such as a web system for example, releasing a new version of a library all the time can be bad for the following reasons:
- Updating a dependency is a time-consuming process, no matter how automated.
- A new version arouses interest, makes the person search for what is new being offered by the library, if the interval between versions is short it ends up affecting the sensitivity of this interest. When the version is spaced out, a new version is an event to celebrate and learn about.
Every commit in the main branch must be atomic, that is, it shouldn't depend on a next commit, so the main branch is always available for a new version. This way, any urgency for a new version, whether the reason, can go along with what is already pending to deploy.
This brings us to another important point: the size of the Pull Request. As well described in article Optimal pull request size: "Every team has an optimal pull request size, it’s likely much smaller than you think, and making your pull requests your optimal size will improve the performance of your team".
Semantic Versioning
Versioning is done through the label defined in the Pull Request. These labels are described in the table below:
| Label | Type | Changelog Title | Description |
|---|---|---|---|
version:major | major | 💥 Breaking Change | Increment the major version |
version:minor | minor | 🚀 Enhancement | Increment the minor version |
version:patch | patch | 🐛 Bug Fix | Increment the patch version |
version:performance | patch | 🏎 Performance | Improve performance of an existing feature |
version:internal | none | 🏠 Internal | Changes only affect the internal API and it doesn't generate a new version |
version:docs | none | 📝 Documentation | Changes only affect the documentation |
version:dependencies | none | 🔩 Dependency Updates | Update one or more dependencies version |
version:release | release | - | Creates a release (canary, pre-release or latest release) |
The labels for generating version use the version: prefix to make it easier to identify it among the other labels in the repository.
The major, minor and patch label types are to identify which version increment will be made according to the semver pattern. In case of multiple Pull Requests accumulated to generate the version, the highest hierarchy will be used for the new version.
The release label type will trigger a latest release when the Pull Request is merged in main branch. This type of label does not exclude the use of other version labels.
The defined labels are designed to be simple and to the point, to guarantee the version to be unromantic and unsentimental.
FAQ
This topic answers some of the frequently asked questions about FrontHub Lib Flow.
Why not generate the version using the commit message?
In an ideal world, commits are done calmly and at the right time in the development cycle, but we know the reality is far more chaotic than that:
- Sometimes we want to commit to protect ourselves from the next changes we're going to try;
- We need to change workplace, or we need to hand over an incomplete job to someone else.
- To test the build on the CI, like changing the CircleCI configuration for example, and we need to keep sending commits to run there.
- Tests in external environments, such as staging environment for example, we just need to commit and test the change there.
You can set up a hook to prevent the commit from being non-standard, but you will block the workflow to force the developer to make a release decision, it doesn't seem to be very productive.
The reasons are many, very common in the daily rush. So it's much easier to make version and release decisions when creating the Pull Request, which is the exact moment you stop to think about it.
Why force squash merge?
As pointed out in the answer to the previous question, commit messages on a development branch are often chaotic, as they reflect the development chaos inherent in the work.
For example a typical git log in a development branch:
7hgf8978g9... Added new slideshow feature, task #84839
85493g2458... Fixed slideshow display issue in ie
gh354354gh... wip, done for the week
789fdfffdf... minor alignment issue
9080gf6567... Fixed in code review
gh34839843... minor fix (typo) for 3rd test
All this log that has no relevant meaning will clutter with the log of other branches and will form a big mess in the main branch.
It's all about Readability of the History. Since squash will merge the entire branch into a single commit at merge time, the developer will have a time reserved to describe the work that has been done, just as is done in the Pull Request title. This will generate a clean and organized log on the main branch.
Can I use a develop branch?
No!!!
The develop branch is used in Git Flow, which is a very different flow from GitHub Flow, as a parallel branch to the main branch with an infinite lifetime. This duplication brings extra complexity with no benefit in return.
Can I use a release branch?
Release branches support preparation of a new production release. Since it is necessary to create a Pull Request with a release label, it might lead you to believe that you need a release branch, but if all the code to be released is in the main branch, what would be in this release branch?
Creating a new branch just for release will only bureaucratize the release, ideally the release label is added in the last Pull Request to be deployed. In case you forgot, here's how to fix it manually.
How do I test two or more branches together?
You can create a new branch with all branches together, open a Pull Request, add the label version:release and use the canary version that will be generated on it. After doing all the tests, just cancel the Pull Request and delete the branch.
But be careful! If you need to do this constantly, it's because your workflow isn't being efficient. Read the topic Continuous Delivery to more information.
How do I test in a staging environment?
The canary version is all you need to test your library in any environment you need.
Just add the label add the label version:release.
Warning: When your PR is merged, the version:release tag will also publish a new version. If you only require the canary for testing, remember to remove the tag after it has been published.
Your branch has to be constantly updated with the main branch, so there's nothing there that wouldn't be on your branch. If you need to test with another branch, read the answer to the previous question.
What if I forget or choose the wrong label for my Pull Request?
The build is configured to validate if your Pull Request has a versioning label added, breaking the CI if you have forgotten it, avoiding any forgetfulness or unfamiliarity problems.
If you change your mind about a version before generating a latest version, you can modify the Pull Request any way you like, even if the Pull Request is already closed.
Once the final version is published, there's no going back. It's important to keep the Changelog the way it is too, so it doesn't have an inconsistency with the generated version.
Can I customize or add new labels?
We suggest that you only customize the titles that will be used in the Changelog, but don't modify the other attributes, as well as don't create other labels.
These labels were designed to simplify the choice of release, but without missing any options. Adding more labels will only hinder decision making. Read more about labels and motivation in the topic Semantic Versioning.
Does Dependabot work with this flow?
It works perfectly! You can configure Dependabot to automatically add the label to your Pull requests:
version: 2
updates:
- package-ecosystem: 'npm'
directory: '/'
schedule:
interval: 'daily'
# Specify the label here
labels:
- 'version:dependencies'
The label version:dependencies add this update to the topic "🔩 Dependency Updates" in Changelog and don't bump the version.
Why doesn't dependency update generate a new version?
The process of updating dependencies is often automated, like using Dependabot for example, so it makes more sense to wrap the updates into a single version. See the Continuous Delivery topic to understand the motivation.
If any dependency update requires a new version, due to a security fix or something like that, just add a label with the increment you want to bump, and if you already want to publish directly in the Pull request, just add the version label. As simple as that.
Constantly publishing a canary version can be a problem?
No matter how good the test is in the development environment, testing the published package will always be the best way to ensure that the library will work in its final version.
Once the new version (latest) is published, in most npm registry, there is no going back, so any fix is only possible with another new version. Canary version testing avoids submitting buggy versions.
In terms of cost, you can confirm in NPM Pricing that it offers "Unlimited public packages" in the free plan and "Unlimited private packages" in the paid plan, so there is no problem there. If you use another npm registry, you must evaluate your billing method.